

Deep NPL per l’identificazione di linguaggio offensivo
Al giorno d’oggi, l’influenza dei social media e dei social network gioca un ruolo importante all’interno della nostra società a prescindere dal paese in cui si vive. Il link qui in basso mostra una chiara rappresentazione della sua incredibile crescita.
http://www.internetlivestats.com/
Ogni giorno sono postati più di 8.000 tweets al secondo che sommano a circa 260 miliardi di tweet all’anno. Questa incredibile mole di testo incorpora un’imponente qunatità di informazione dal quale possono essere estratti spunti importanti. L’analisi testuale qui descritta fa capo al più ampio mondo del processamento naturale del linguaggio (Natural Language Processing – NPL).
L’obiettivo di questo post è quello di presentare una procedura pratica e semplice da implementare per il riconoscimento del linguaggio offensivo e\o discriminatorio all’interno di tweet. Sebbene non sia presente alcuna definizione universale di linguaggio offensivo, la più esaustiva può essere considerata quella offerta da Nockleby (2000):
‘Ogni comunicazione che discrimina uno specifico gruppo di persone target sulla base di alcune caratteristiche quali razza, colore della pelle, etnia, genere, orientamento sessuale, nazionalità, religione o altre caratteristiche’.
L’articolo è strutturato nel seguente modo: in primo luogo, sarà effettuata una breve descrizione del dataset (ottenuto combinando diverse fonti). In secondo luogo, sarà descritto il fondamentale step riguardante il preprocessamento dei dati al fine di mostrare, passo per passo, i step necessari per una corretta implementazione dell’analisi. In ultimo, si propone un semplice modello basato su reti neurali e un’apposita rappresentazione degli stessi.
Dataset per tweet contenenti linguaggio offensivo
Al fine di sviluppare l’analisi in modo intuitivo, ma non esaustivo, saranno utilizzati differenti tipologie di dataset. Il primo tra questi può essere ottenuto tramite il link seguente: https://data.world/datasets/hate-speech. A questo link sono disponibili sei dataset differenti ampiamente utilizzati nella ricerca scientifica e nell’analisi testuale. Nel complesso, l’analisi che si vuole effettuare sfrutta 55.000 tweet derivanti dell’agglomerazione di questi dataset. Dal momento che siamo interessati a sviluppare modelli di machine learning basati su reti neurali, ed in particolar modo riguardanti il deep learning, abbiamo bisogno di una mole di dati consistente al fine di poter trainare la rete in modo appropriato. Per tale ragione, si propone un ulteriore dataset disponibile al seguente link: https://github.com/aitor-garcia-p/hate-speech-dataset. Per questo dataset, è disponibile in interessante paper dal titolo: “Hate Speech Dataset from a White Supremacy Forum”. Il dataset è disponibile in formato ‘txt’ nel quale ogni tweet si presenta all’interno un file di testo singolo. Al fine di assolvere al compito riguardante la concatenazione di questi tweet in un unico file ‘csv’, si propone l’utilizzo di un semplice comando bash:

Con questo semplice comando siamo in grado di iterare all’interno della directory in cui siamo presenti al fine di appendere (comando ‘cat’) ogni file che presenta un’estensione ‘.txt’ e ridenominate il file finale ‘all_tweets.csv’. Al fine d rendere la lettura della linea di codice più agevole il delimitatore considerato per identificare una nuova osservazione è ‘;…;’ posto dopo il comando ‘echo’. Si suggerisce l’incapsulamento dell’indice ‘$i’ all’interno di apici al fine di evitare errori nel caso il nome del file contenga spazi bianchi. Se siete curiosi di scoprire di più sul mondo bash e su altri interessanti comandi, vi suggerisco di dare un’occhiata al seguente link: http://mywiki.wooledge.org/BashPitfalls#line-8 nel quale sono mostrati non solo i più comuni errori che commettono i programmatori bash neofiti ma anche la più appropriata soluzione.
Un ulteriore dataset considerato per l’analisi oggetto di questo articolo è derivante da Kaggle tramite la competizione: “Twitter hate speech”. Per questo dataset, sono disponibili due file in formato ‘csv’ che fanno riferimento rispettivamente al training ed al test set. Per questo dataset, sono disponibili poco meno di 30.000 label univoci. Tali tweet sono quindi concatenati ai dataset precedentemente discussi.
In ultimo, sempre sul sito Kaggle, è presente un altro interessante dataset messo a disposizione tramite la competizione: “Toxic Comment Classification Challenge” che propone una valutazione di testi contenenti minacce, abusi e molestie su un grandissimo numero di recensioni e commenti raccolti da Wikipedia ed i quali sono stati accuratamente labellati da persone le quali hanno valutato il grado e la tipologia di linguaggio offensivo e\o violento. In tal caso, sono identificate sei tipologie di linguaggio violento. Tuttavia, al fine di mantenere la trattazione semplice, tale categorizzazione è stata codificata in un’unica variabile binaria che descrive la semplice presenza o assenza di linguaggio offensivo. Da notare che, sebbene tale dataset non fa riferimento a tweet, è stato considerato ugualmente al fine di espandere l’analisi e offrire una maggior accuratezza all’analisi.
Pre-processing… uno step avanti verso la ‘vera’ analisi
Tutti noi siamo ben consapevoli che, prima di poter utilizzare algoritmi di machine learning (ML) abbiamo bisogni di rendere il nostro dataset ‘feasible’ (fattibile) per l’analisi che si vuole sviluppare. Questa fase di preprocessamento dei dati risulta particolarmente importante quando si lavora con dati in formato testo. Gran parte delle parole che costituiscono una frase, infatti, non sono utili al task che si vuole sviluppare. L’obiettivo, in questa fase, è rendere la vita del nostro classificatore più semplice possibile per poterne massimizzare le performance. Di seguito vi presentiamo alcune semplici funzioni per la pulitura, non esaustiva, del testo:
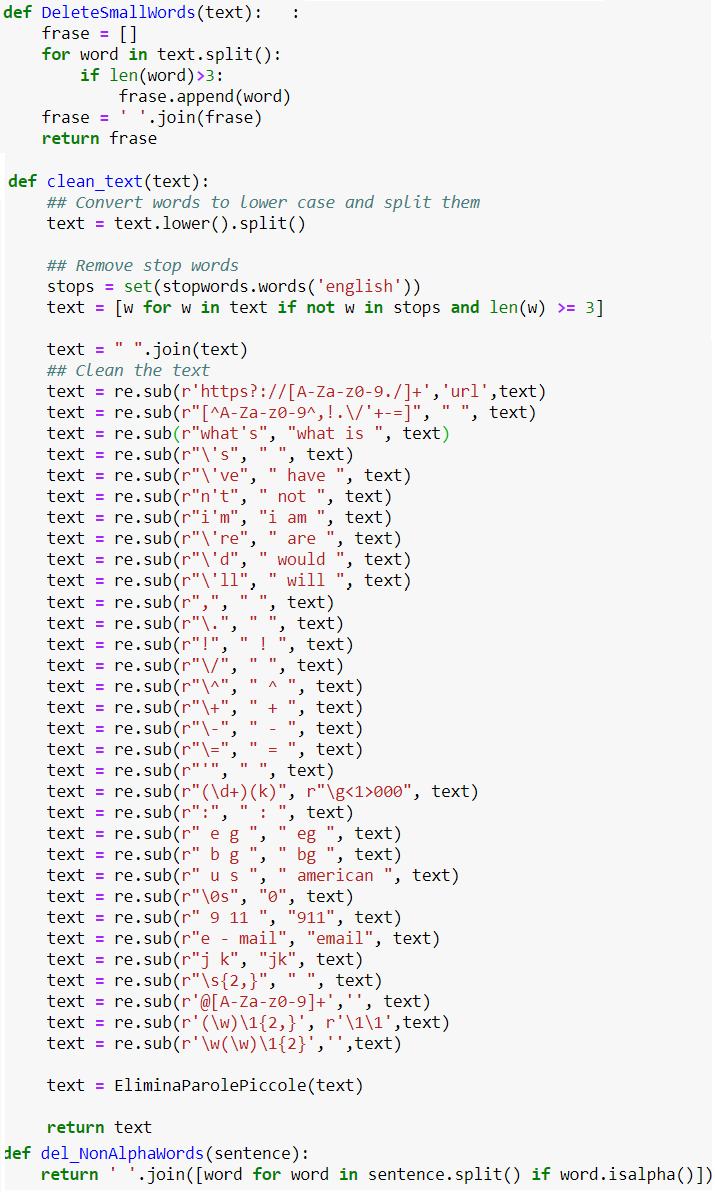
Codice utile alla pulitura del dataset durante la fase di preprocessamente del dataset
Dopo aver eliminato alcune parole o simboli di punteggiatura dal nostro dataset, abbiamo bisogno di rendere i tweet comprensibili agli occhi del classificatore. La rete neurale, ed in generale tutti gli algoritmi ML non sono in gradi di interpretare testi. Per consentire la trattazione di questi dati, quindi, abbiamo bisogni di trasformare le parole in una sequenza di numeri che abbiano un senso. Fortunatamente, Keras, in questo caso, viene in nostro soccorso offrendoci il package chiamato: “Tokenizer” che ci consente di effettuare questo step in un modo molto semplice utilizzando poche semplici linee di codice:
![]()
Istanziazione dell’oggetto Tokenizer
Con questa linea di codice creiamo un’istanza dell’oggetto Tokenizer nel quale abbiamo bisogno di definire solamente la dimensione del nostro dizionario. Per fini espositivi, per questa particolare analisi, si propone un dizionario di 10.000 parole. Lo step successivo è quello di fittare e trasformare i dati:

Fitting e trasformazione del dataset in sequenze
Si noti che prima di effettuare questa operazione è necessario effettuare il train-test-split del dataset dal momento che il test set deve essere codificato secondo quanto appreso dal training set (altrimenti stiamo “barando”!!!).
In ultimo, abbiamo bisogno di uguagliare la lunghezza di ogni tweet per rendere possibile l’analisi tramite l’utilizzo delle rei neurali. Questo processo di “equal-length” prende il nome di “padding” ed è anch’esso molto semplice da implementare (grazie ancora Keras!!!):
![]()
Padding method for equal length sequences
Da notare che il metodo “pad_sequences” prende come input una lista di tweet. Abbiamo, inoltre, bisogno di specificare la lunghezza massima al quale vogliamo eguagliare ogni frase. Frasi più corte rispetto al massimo (“input_length”) saranno espanse aggiungendo zeri all’inizio della sequenza mentre frasi più lunghe saranno troncate. Per questa analisi si propone una lunghezza massima pari a 15.
Quasi fatto… solamente un ultimo importantissimo step chiamato: “pre-trained Glove embedding”. Ti senti confuso a tal riguardo? Questa è la definizione che il Gruppo Stanford offre per descriverlo:
‘Glove è un algoritmo non supervisionato per l’ottenimento di una rappresentazione vettoriale delle parole. La fase di training è sviluppata sfruttando statistiche riguardanti aggregazioni di parole ad occorrenza concomitante (word-word co-occurrence), dove la rappresentazione risultante esibisce sottostrutture lineari dello spazio vettoriale delle parole.’
Con il termine “word embedding” si fa riferimento al processo di associazione di ogni parola presente all’interno del dizionario con un vettore di lunghezza ‘n’ (definito come vettore n-dimensionale). In sostanza, ogni parola, e quindi ogni numero ad essa associato, è collegato ad un vettore. Il fine di espandere la rappresentazione di ogni parola in uno spazio di rappresentazione più ampio è duplice:
Motivazione 1 — (e la più importante): questo vettore n-dimensionale è stato generato da un modello di rete neurale trainato su alcuni miliardi di parole. L’obiettivo della rete è quello di posizionare, all’interno dello spazio n-dimensionale, parole con significato simile vicine tra loro, come ad esempio cane e gatto, frutta e albero ecc..
Motivazione 2: l’espansione della dimensionalità delle features porta ad una migliore discriminazione\classificazione della funzione obiettivo. Questo processo viene comunemente chiamato “kernel trick”: (https://towardsdatascience.com/understanding-the-kernel-trick-e0bc6112ef78):
‘alcuni dati che non sono separabili nello spazio di rappresentazione originale diventano separabili in uno spazio dimensionale più ampio’.
Questo è il link da cui è possibile scaricare il “Glove embedding dictionary”: https://www.kaggle.com/jdpaletto/glove-global-vectors-for-word-representation
Per l’analisi in oggetto, è stato utilizzato il file: ‘glove.twitter.27B.200d.txt’. Di seguito è mostrato il codice per effettuare il linkage tra il nostro vocabolario e la rappresentazione n-dimensionale di Glove:
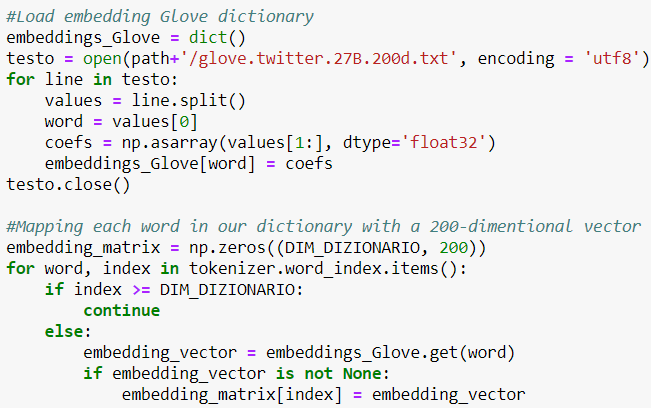
Codice per la mappatura del dizionario tramite l’embedding offerto da Glove
A simple Neural Network for hate speech detection
Dopo il noioso preprocesamento del dataset, siamo pronti ad implementare l’analisi. Data la bassa dimensionalità del dataset, si propone una rete neurale molto semplice contenente solamente un layer LSTM con 10 neuroni:
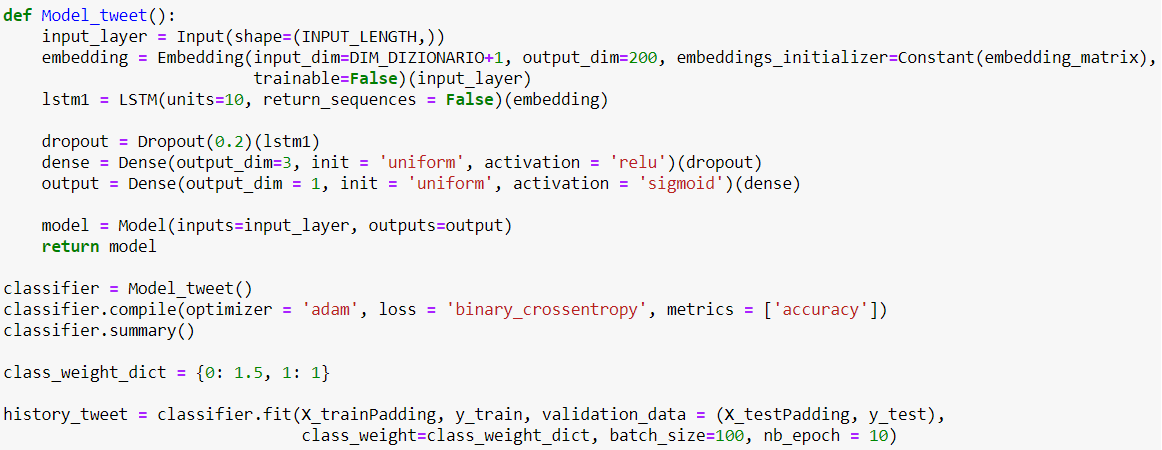
Modello di rete neurale per l’identificazione di linguaggio offensivo
Dal codice sopra, è possibile notare che il secondo layer del modello è l’embedding al quale viene imposto la caratteristica di non essere trainabile (trainable=False). La “non trainabilità” di questo strato della rete è dovuta al fatto che una rappresentazione multidimensionale dei dati risulta particolarmente costosa sia in termini computazionali che in termini di accuratezza (se non si hanno sufficienti dati per addestrarla). Glove, d’altra parte, è addestrata su una mole enorme di dati (dell’ordine di miliardi) raggiungendo in questo modo un’impressionante grado di accuratezza. Questa conoscenza offerta da Glove viene sfruttata per inizializzare l’embedding layer tramite la matrice creata precedentemente (chiamata ‘embedding_matrix’). In ultimo, abbiamo aggiunto uno strato di “dropout” al fine di evitare (o al minimo di limitare) il potenziale problema di overfitting.
Un interessante nota riguarda il parametro “class_weight” all’interno del metodo “fit”. Tutte le volte in cui ci troviamo ad avere un dataset sbilanciato, è possibile procedere effettuando un resampling del dataset per pareggiare la classe meno numerosa (upsampling) o ridurre quella più numerosa (downsampling). In alternativa, si ha la possibilità di sfruttare il metodo offerto da Keras. Per questa analisi è stata utilizzata la seconda scelta in cui, fornendo semplicemente un dizionario, è possibile definire i pesi da associare ad ogni classe. Il risultato della fase di training è presentato nel grafico sottostante:
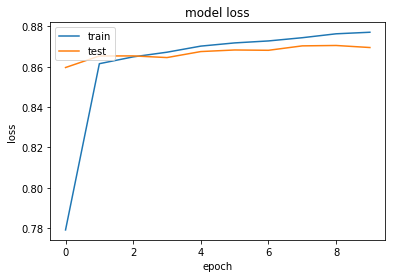
Performance del modello: funzione di perdita relativa alla fase di training e testing per ogni epoch
Dal grafico è possibile notare come il modello raggiunga un buon livello di performance. In aggiunta, la tabella seguente, mostra il report della classificazione. Il coefficiente di “total weighted f1-score” si attesta al 87% e il maggior contributo a tale score è fornito dalla classe labellata con zero (not-abusive).
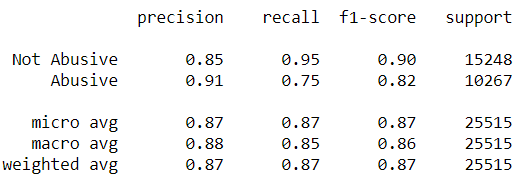
Classification Report: Abusive vs Not-Abusive accuracy
Al fine di ottenere un’interessante rappresentazione dell’output prodotto dalla rete, proponiamo due WordCloud, con annesso codice python, rispettivamente per i tweet classificati positivamente e per quelli che presentano un’accezione negativa. Ad esse è stata imposta una maschera per una più significativa rappresentazione e trasmissione del messaggio. Di seguito il codice per realizzarle:
Python Code

Codice per l’implementazione della WordCloud tramite l’imposizione di una maschera
Positive predicted tweets

WordCloud per tweet con accezione positiva
Negative predicted tweets
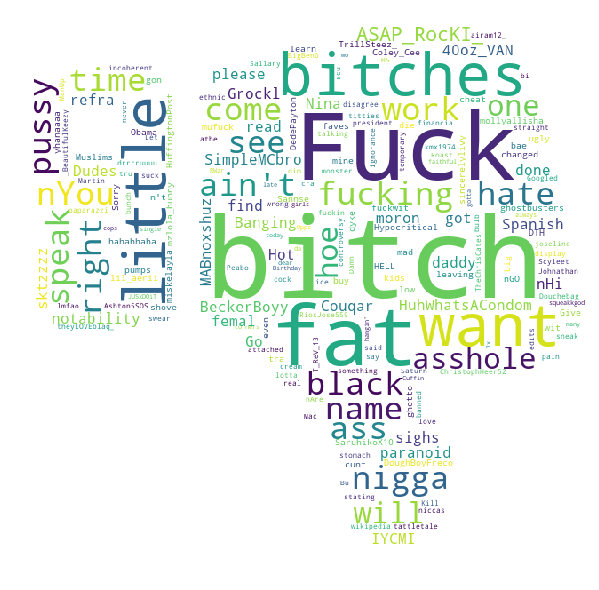
WordCloud per tweet con accezione negativa
Risulta intuitivo notare che la WordCloud di parole positive\non-offensive (pollice verso l’alto) continente parole come: benvenuto, potrei, piacere, gentile (mostrate in questo contesto in lingua inglese), mentre frasi con accezione negativa presentano parole offensive di evidente natura.
Come nota finale, inoltre, per quel che concerne l’analisi del sentimento in lingua italiana, non esistono, finora package in grado di assolvere al compito. Al fine sviluppare il task in parola, proponiamo un semplice passaggio tramite l’utilizzo del package chiamato “TextBlob”. Tale procedura è alquanto semplice, in primo luogo traduciamo il testo da italiano ad inglese tramite il suddetto package. Successivamente, applichiamo il modello di rete neurale visto in precedenza.
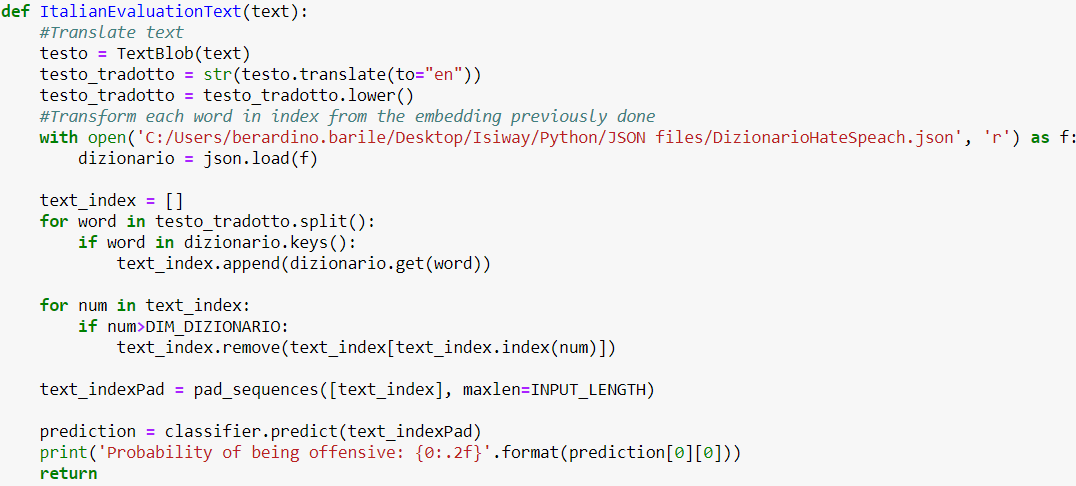
Codice per la valutazione di tweet in lingua italiana
Con “TextBlob” traduciamo il testo da italiano a inglese e mappiamo ogni parola così ottenuta con l’appropriato indice salvato nel nostro dizionario durante la fase di training del modello. Di seguito mostriamo i risultati ottenuti sia nel caso di frasi neutrali che di quelle con accezione negativa\offensiva:

Tweet con accezione non offensiva in lingua italiana

Tweet con accezione offensiva in lingua italiana
Dal momento che la frase con accezione negativa risulta particolarmente offensiva si è preferito censurare la stessa. Il significato rimane tuttavia alquanto evidente.
Conclusioni
In questo articolo, è stata offerta una breve introduzione riguardo all’utilizzo del deep learning inerenti l’analisi del linguaggio naturale. In primo luogo, abbiamo mostrato come implementare il fondamentale step inerente il preprocessamento dei dati. In questa sezione sono state discusse le principali tecniche e metodologie più comunemente utilizzate tra cui si citano il processo di “parsing” al fine di rimuove parti di testo, parole e punteggiatura non utili all’assolvimento del compito di classificazione. Seguono la procedura di “tokenizzazione”, di “stemming” e “padding” per l’ottenimento di un adeguato set di dati utilizzabile dall’algoritmo ML. A seguire, si è mostrata la procedura di “embedding” che rappresenta un fondamentale e non trascurabile step per il miglioramento e la rappresentazione del set di dati in uno spazio n-dimensionale. In questa fase si è mostrato il “perchè” sia necessario effettuare tale procedura e come effettivamente essa può essere implementata. La conoscenza fornita da Glove, quindi, viene passata al nostro modello di rete neurale che, tramite l’apposito strato di embedding associa, ad ogni parola presente all’interno del dizionario, un vettore di dimensione ‘n’. Per far ciò, tuttavia, è necessario imporre la condizione di non trainabilità del suddetto layer (trainable=False). Una volta allenato il modello, si è proceduto alla valutazione dello stesso e si sono forniti il grafico relativo alla performance durante la fase di training e la tabella relativa alla report classification che ci ha consentito di valutare la bontà della metodologia proposta. In ultimo, per una rappresentazione dei risultati più appealling, si sono mostrate due rappresentazione, tramite due distinte WordCloud, rispettivamente riguardanti le parole più comunemente utilizzate in tweet con accezione neutrale rispetto a quelli con accezione offensiva. Per motivi puramente estetici è stata imposta una maschera ad entrambe le rappresentazioni ed è stato mostrato il relativo codice per realizzarle.
Potete trovare la versione in inglese su questo link:
https://medium.com/isiway-tech/deep-nlp-for-hate-speech-detection-25eed707997