

Machine Learning: come scegliere il modello migliore
Scelta del modello migliore
Una delle fasi più importanti del machine learning riguarda la scelta del cosiddetto “modello migliore”.
Che si tratti di regressione logistica, Random Forest, metodi bayesiani, Support Vector Machine (SVM) o reti neurali, non esiste un modello ideale che si possa definire migliore di altri, esiste un “modello più adeguato” ai dati ed al contesto in cui andrà ad operare.
Prima di affrontare questo tema molto importante, facciamo una breve introduzione al Machine Learning.
Il Machine Learning (ML) è una branca all’interno del più ampio mondo dell’Intelligenza Artificiale e si pone l’obiettivo di far apprendere alle macchine, in modo automatico, attività svolte da noi esseri umani.
Il termine Machine Learning fu coniato per la prima volta nel 1959 da Arthur Samuel e ripreso successivamente da Tom Mitchell che ne ha dato una definizione formale e attuale:
“Si dice che un programma impara da una certa esperienza E rispetto a una classe di compiti T ottenendo una performance P, se la sua performance nel realizzare i compiti T, misurata dalla performance P, migliora con l’esperienza E.”
C’è una leggera differenza tra algoritmo tradizionale e algoritmo di machine learning.
Nel primo caso il programmatore definisce i parametri e i dati necessari alla risoluzione dell’attività; nel secondo caso, dovendo trattare problemi per i quali non esistono strategie predefinite o non si conosce un modello, si fa in modo che il computer impari eseguendo l’attività e migliorando l’esecuzione della stessa.
Ad esempio, un programma di un personal computer può risolvere il gioco Tris e riuscire a batterti perché è stato programmato con una strategia vincente per farlo; ma se non conoscesse le regole basi del gioco occorrerebbe scrivere un algoritmo che, giocando, apprende automaticamente tali regole finché non sarà in grado di vincere.
Il computer in quest’ultimo caso non si limita ad eseguire una “mossa” ma piuttosto cerca di capire quale potrebbe essere la migliore: attraverso i vari esempi che otterrà giocando costruisce le regole che descrivono tali esempi e riuscirà a comprendere autonomamente se il nuovo caso corrisponde alla regola che ha ricavato e di conseguenza deciderà la mossa da effettuare.
Dunque, il Machine Learning ha l’obbiettivo di creare modelli che permettono di costruire algoritmi di apprendimento per risolvere uno specifico problema.
Il modello di apprendimento indica lo scopo dell’analisi, ossia come si vuole che impari l’algoritmo.
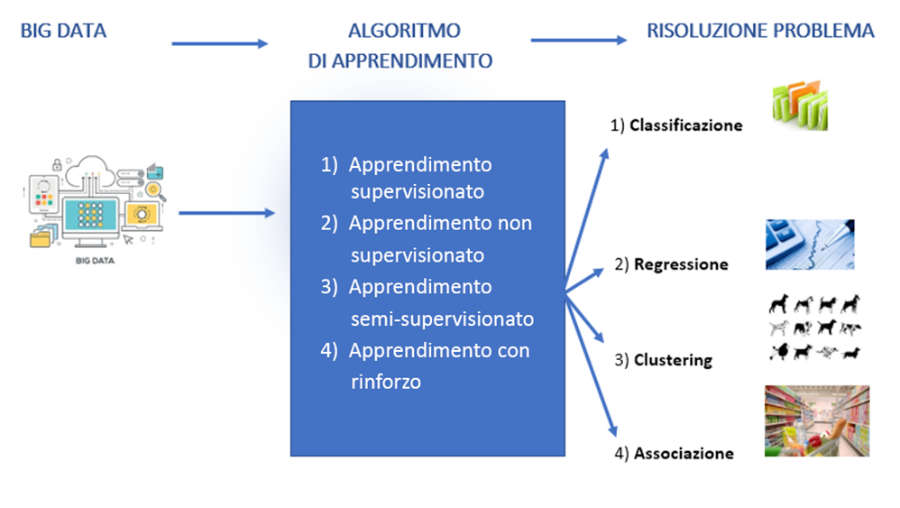
Esistono vari modelli di apprendimento:
Apprendimento supervisionato (Supervised Learning)
In questo primo caso, il processo di un algoritmo che apprende dal set di dati di addestramento può essere pensato come un insegnante che supervisiona il processo di apprendimento. L’apprendimento si interrompe quando l’algoritmo raggiunge un livello accettabile di prestazioni.
L’apprendimento supervisionato si ha quando si hanno dati di input (X) e dati di output (Y) e si utilizza un algoritmo che apprende la funzione che dall’input genera l’output.
L’obiettivo è approssimare la funzione in modo che quando si ha un nuovo dato di input (X) l’algoritmo può prevedere il valore di output generato (Y) per quel dato.
I problemi di apprendimento supervisionato si possono dividere in:
1) Classificazione: è il processo in cui una macchina è in grado di riconoscere e categorizzare oggetti dimensionali da un set di dati.
2) Regressione: rappresenta il fatto che una macchina può predire il valore di ciò che sta analizzando in base a dati attuali. In altre parole, studia la relazione tra due o più variabili una indipendente dall’altra.
Ad esempio, data l’ampiezza di una casa prevederne il prezzo, oppure cercare la relazione tra le gare automobilistiche e il numero di incidenti effettuati da un pilota.
3) Apprendimento non supervisionato (Unsupervised Learning)
L’apprendimento senza supervisore è quando si ha una variabile di input (X), rappresentata dai dati, e nessuna variabile di output corrispondente.
Si pone l’obiettivo di trovare relazioni o schemi tra i vari dati che vengono analizzati senza utilizzare una categorizzazione come visto per gli algoritmi Supervised Learning.
L’apprendimento si dice “non supervisionato” perché non ci sono risposte corrette e non c’è un insegnante.
Gli algoritmi sono lasciati a sé stessi per scoprire e presentare l’interessante struttura dei dati.
I problemi di apprendimento non supervisionato si possono dividere in:
3.1) Raggruppamento: detto anche “clustering”, viene utilizzato quando è necessario raggruppare i dati che presentano caratteristiche simili.
In questo caso l’algoritmo impara se e quando individua una relazione tra i dati.
Il programma non utilizza dati categorizzati in precedenza ma estrae una regola che raggruppa i casi presentati secondo caratteristiche che ricava dai dati stessi.
Non viene specificato al programma cosa rappresentano i dati e per questo motivo risulta più complesso determinare l’affidabilità del risultato.
3.2) Associazione: è un problema in cui si vogliono scoprire regole che descrivono grandi porzioni dei dati disponibili come, ad esempio, le persone che acquistano un prodotto A tendono anche ad acquistare un prodotto B.
Si pone l’obiettivo di trovare schemi frequenti, associazioni, correlazioni o strutture casuali tra un insieme di item od oggetti in un database relazionale.
Dato un set di transazioni, cerca di scoprire regole che predicono l’evento di un item in base agli eventi di altri item nella transazione. È strettamente collegato al Data Mining.
Apprendimento con rinforzo (Reinforcement Learning)
Tecnica di machine learning che rappresenta la versione computerizzata dell’apprendimento umano per tentativi ed errori.
L’algoritmo si presta ad apprendere e ad adattarsi ai cambiamenti ambientali tramite un sistema di valutazione, che stabilisce una ricompensa se l’azione compiuta è corretta, oppure una penalità nel caso opposto.
L’obiettivo è quello di massimizzare la ricompensa ricevuta, senza che venga annunciata la strada da intraprendere.
Dopo questa introduzione al Machine Learning ed ai vari modelli di addestramento, affrontiamo il tema della scelta del modello giusto sulla base di dati e della conoscenza.
Nel tempo ogni modello di addestramento si è evoluto su vari algoritmi più o meno complessi e sofisticati.
La produzione di un buon modello dipende in modo critico dalla selezione e dall’ottimizzazione delle caratteristiche, nonché dalla selezione del modello stesso.
Il processo per poter individuare il modello migliore è un percorso complesso e iterativo.
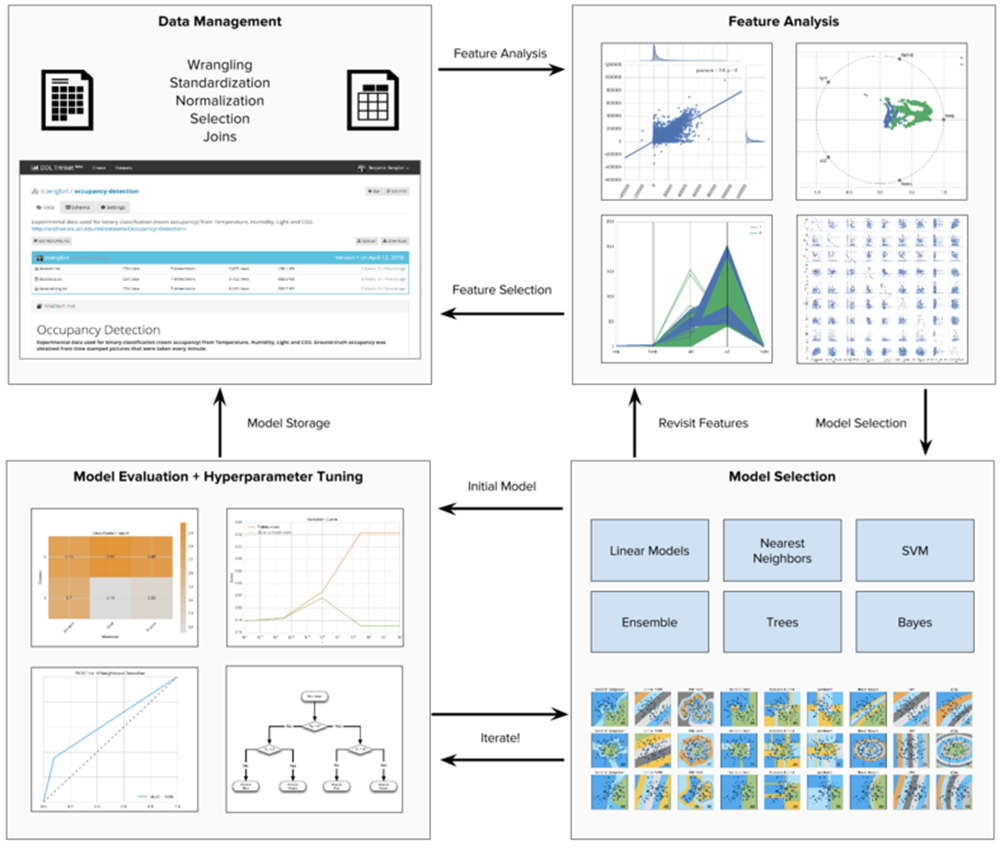
Come mostrato nel diagramma, si inizia con l’analisi delle caratteristiche utilizzando istogrammi, grafici a dispersione e altri strumenti visivi. Questa fase importante si chiama EDA (Exploratory Data Analysis)
Poi si effettua l’analisi delle caratteristiche dei dati, dove si eseguono le normalizzazioni, i ridimensionamenti e l’estrazione degli attributi.
Dopo questa fase, che ci permette di analizzare i dati e di capire il contesto, si identifica la categoria di modelli di machine learning più adatta agli obiettivi e allo spazio problematico, spesso sperimentando la previsione dell’adattamento su più modelli.
Questa fase viene iterata tra valutazione e messa a punto utilizzando una combinazione di strumenti numerici e visivi come curve ROC, grafici dei residui, mappe di calore e curve di convalida.
Uno dei metodi che utilizziamo durante questa fase di scelta del modello è descritta dalla libreria Scikit-Learn tramite l’utilizzo del seguente diagramma.
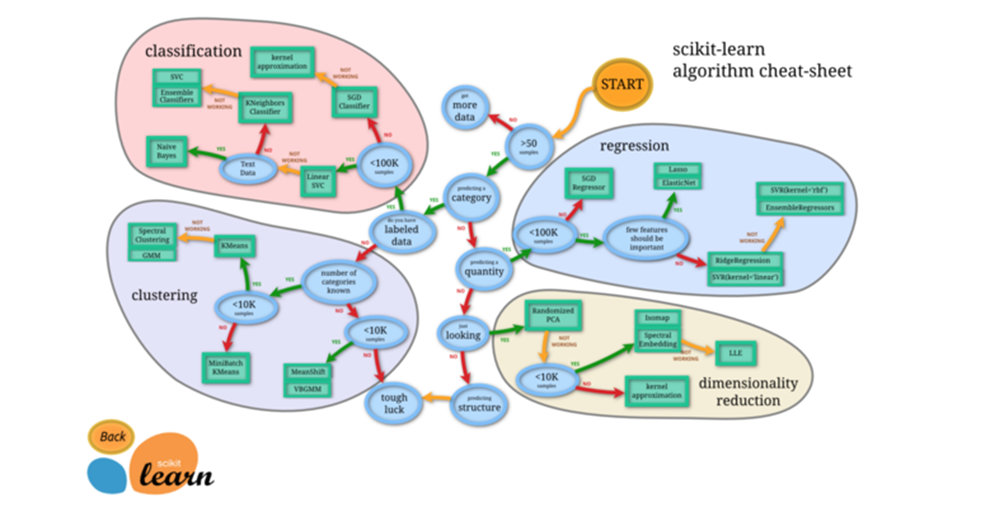
Questo diagramma è utile per una prima fase, poiché modella un processo decisionale semplificato per la selezione dell’algoritmo di apprendimento automatico più adatto al proprio set di dati.
Il diagramma di flusso Scikit-Learn è utile perché ci offre una mappa, ma non offre molto in termini di trasparenza su come funzionano i vari modelli.
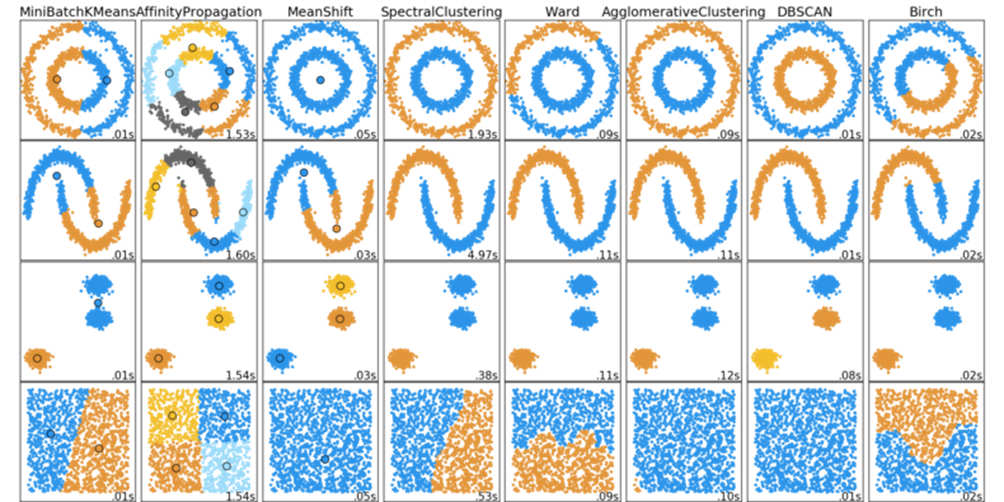
Per questo tipo di approfondimento, ci sono due immagini che sono diventate in qualche modo canoniche nella comunità Scikit-Learn: il confronto dei classificatori e i grafici di confronto dei clustering.
Poiché l’apprendimento senza supervisione viene eseguito senza il vantaggio di avere i dati etichettati, il grafico “confronto dei clustering” è un modo utile per confrontare diversi algoritmi di clustering tra diversi set di dati:
Allo stesso modo, il grafico che segue di confronto dei classificatori è una utile comparazione visiva delle prestazioni di nove diversi classificatori in tre diversi set di dati:
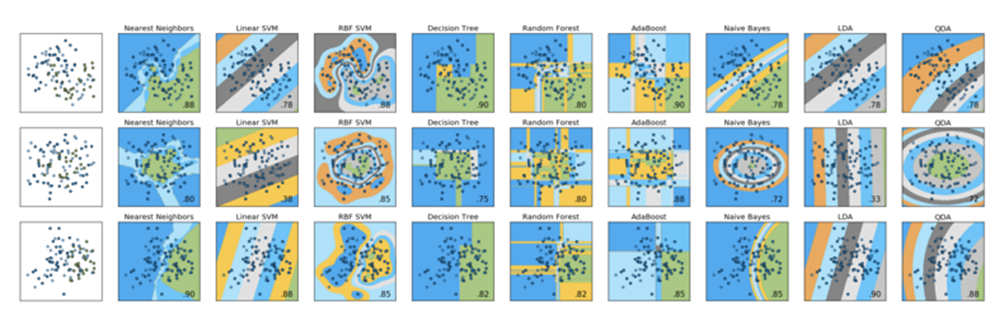
In genere queste immagini vengono utilizzate solo per dimostrare le differenze sostanziali nelle prestazioni di vari modelli tra diversi set di dati.
Ma cosa si fa quando hai esaurito tutte quelle opzioni? Ci sono molti più modelli disponibili in Scikit-Learn e il diagramma di flusso precedentemente visto è a malapena la superficie. È possibile utilizzare un approccio esaustivo per testare essenzialmente l’intero catalogo di modelli Scikit-Learn al fine di trovare quello che funziona meglio sul proprio set di dati.
Ma se il nostro obiettivo è quello di essere “professionisti del Machine Learning” più informati, allora ci preoccupiamo non solo del funzionamento dei nostri modelli, ma anche del perché stanno, o non stanno, funzionano.
Per i nostri scopi, la sperimentazione, all’interno dei moduli del modello, e degli “iperparametri”, è probabilmente il luogo per ottenere la scelta del modello migliore.
Uno strumento che viene utilizzato per l’esplorazione del modello è la mappa interattiva di data mining del Dr. Saed Sayad
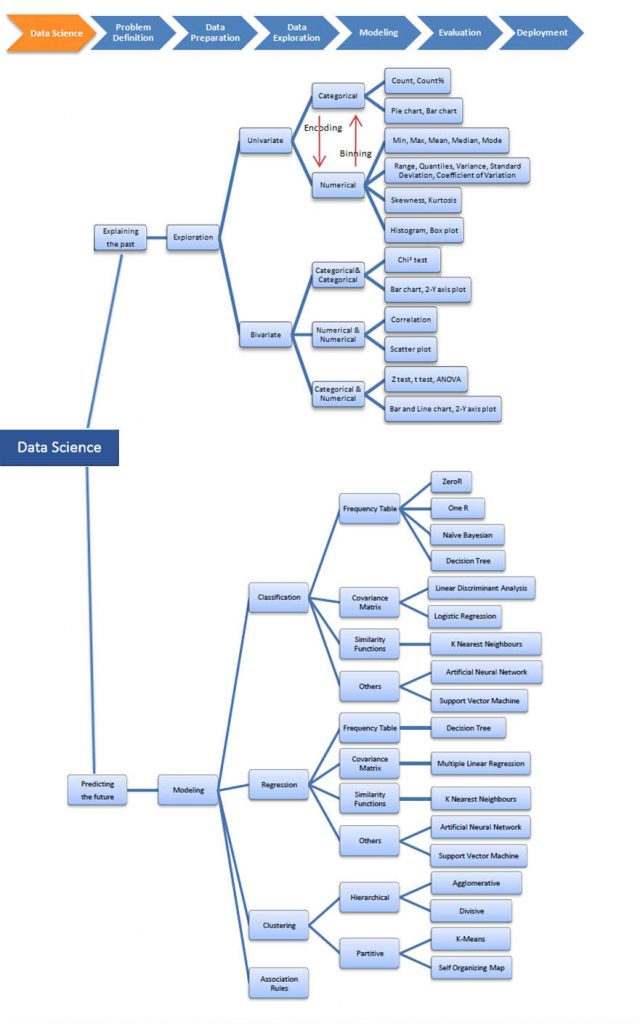
https://www.saedsayad.com/data_mining_map.htm
Molto più esaustiva del diagramma di flusso Scikit-Learn poiché integra altri modelli ed inoltre, oltre ai metodi predittivi, include una sezione separata sui metodi statistici, la parte di esplorazione (EDA) e normalizzazione dei dati.
Di seguito è riportata un’iterazione su un grafico che invece abbiamo creato nel Area R&D di Humanativa, e che ha lo scopo di presentare la stessa ampia copertura di metodi predittivi di Sayad (rappresentandone alcuni, come l’apprendimento per rinforzo, non rappresentati nell’originale), mentre integra il diagramma di Scikit-Learn.
Il colore e la gerarchia definiscono le forme del modello e le famiglie di modelli:
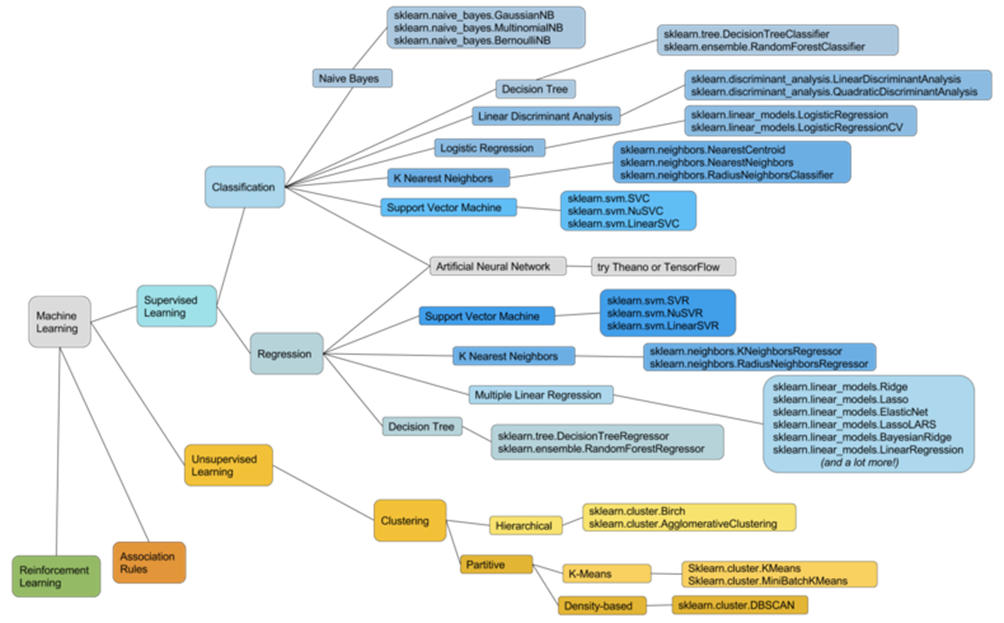
Sebbene questa mappa non sia completa, l’obbiettivo è che diventi uno strumento, che sulla base dellenostra esperienza, ci permetta di selezionare più velocemente i modelli da testare sulla base dei dati disponibili.