

Deep Learning la tecnologia del futuro, cosa è e perché rappresenta la prossima frontiera di Humanativa
In questi anni l’attività di ricerca e sviluppo realizzata da Humanativa è stata rivolta al tema del Machine Learning attraverso la sperimentazione di diversi modelli di Deep Learning.
Nel 2022 il nostro obiettivo è rafforzare questa competenza, una scelta strategica avvalorata da osservatori e analisti a livello mondiale, concordi nel sostenere che tale tecnologia sarà fortemente utilizzata nei prossimi anni, soprattutto con l’arrivo dei fondi europei del PNRR.
La serie di articoli che dedicheremo a questa tecnologia ha lo scopo non solo di analizzarne gli aspetti tecnici ma anche di condividere i progetti che Humanativa sta avviando in tale ambito.
Reti neurali umane e reti neurali artificiali
Il meccanismo di funzionamento delle reti neurali umane è oggi utilizzato come modello per indirizzare molteplici applicazioni di intelligenza artificiale, quali il riconoscimento immagini, il voice recognition, le applicazioni biometriche, la guida autonoma e i simulatori di varia natura.
Ma come funzionano le reti neurali?
I neuroni, le cellule fondamentali del cervello, sono composti da una parte di nucleo circondato dal corpo del neurone, detto anche soma. Il nucleo è collegato ad altri neuroni attraverso due tipologie di ramificazioni: i dendriti([1]), che raccolgono gli input, e gli assoni([2]), che emettono gli output.
Sono le sinapsi a fungere da connettori tra assoni e dendriti, consentendo il passaggio delle informazioni tra un neurone e l’altro.
Tramite processi elettrochimici, la sinapsi invia degli impulsi lungo il proprio assone, attivando così input elettrici verso i dendriti del neurone successivo.
L’efficacia di questi impulsi a livello sinaptico è legata ai processi di apprendimento e alla memoria dell’essere umano e viene o meno rafforzata attraverso un processo di reweighting o di riponderazione.
Il cervello umano contiene circa cento miliardi di neuroni e ognuno di essi può essere collegato mediamente con altri mille neuroni. Se moltiplichiamo i due numeri, otteniamo un potenziale di 10^14 connessioni sinaptiche.
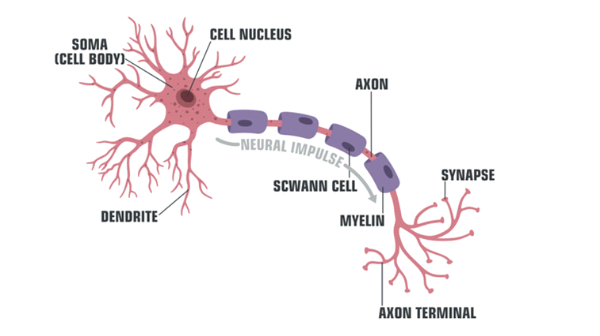
([1]) Porzione ricevente del corpo cellulare del neurone. I dendriti sono spesso numerosi e ramificati e si estendono nell’area circonvicina al corpo cellulare; sulla loro membrana plasmatica stabiliscono contatti sinaptici con le porzioni trasmittenti (gli assoni) dei neuroni presinaptici, e conducono il potenziale elettrico generato dai recettori fino al corpo cellulare e al cono d’emergenza dell’assone della cellula nervosa a cui appartengono.
([2]) Prolungamento della cellula nervosa, in grado di condurre l’impulso nervoso dal corpo cellulare verso la periferia e di trasmetterlo ad altre cellule.
I neuroni sono quasi tutti creati alla nascita, salvo pochissimi che possono crearsi in età post-natale, ma di fatto il neurone è l’unica cellula umana che non può più rigenerarsi dopo la nascita. La rete che li connette – e soprattutto la formazione di nuove sinapsi – risulta rapidissima nei neonati e prosegue anche in età adulta.
Le connessioni sinaptiche potenziate attraverso i processi di reweighting restano attive più a lungo – formando di fatto la memoria a lungo termine – mentre quelle deboli e non utilizzate vengono rimosse insieme ai dendriti a cui sono collegate.
I primi studi di simulazione dei neuroni per creare intelligenze artificiali sono stati enunciati nel Dicembre 1943 da Warren S. McCulloch e Walter Pitts nella pubblicazione intitolata “A logical calculus of the ideas immanent in nervous activity”.
Si tratta di un combinatore basilare con numeri binari multipli in input e un output binario singolo, associato all’idea di poter creare una rete di tali combinatori in modo da effettuare calcoli.
È però nel 1958 che Frank Rosenblatt introduce la prima vera idea di neurone artificiale, chiamato percettrone (perceptron): si tratta di un modello con dati di input pesati, che introduce la prima vera idea di apprendimento, seppure in forma molto elementare. Rappresenta, di fatto, il primo modello di rete neurale artificiale.
Il percettrone è un classificatore binario per apprendimento supervisionato, in grado di predire se il vettore di dati in ingresso con i valori opportunamente pesati, appartenga ad una classe oppure no.
Il classificatore in questione utilizza un algoritmo di classificazione lineare, come quelli che abbiamo già visto, ovvero riceve in input delle variabili Xi e li somma linearmente con pesi Wi (questa parte ricorda un po’ i dendriti dei nostri neuroni)
Y = W1X1 + W2X2 + W3X3 + …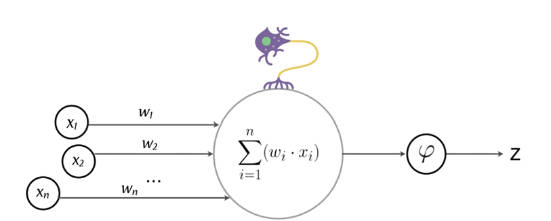
La risultante Y di questo classificatore lineare (l’assone del nostro neurone) è data poi in pasto ad una funzione non lineare chiamata activation function (funzione di attivazione), che possiamo provare ad associare alla sinapsi del neurone biologico.
La funzione di attivazione è una funzione matematica applicata agli input del neurone che ne determina l’output. Esistono varie funzioni di attivazioni che in base alla tipologia di neurone sono utilizzate per ottimizzare l’apprendimento.
Ad esempio, la funzione gradino (utilizzata nella classificazione binaria), la funzione segno, la funzione sigmoide (sig) (utilizzata nella regressione lineare logistica), la funzione tangente iperbolica (tanh) (utilizzata nella regressione lineare logistica), funzione di attivazione ReLu e la funzione SoftMax (utilizzata per la classificazione su diverse classi).
In definitiva possiamo considerare il percettrone come una rete neurale basilare ad un solo livello. Se poi colleghiamo molteplici percettroni in cascata, almeno uno di input, uno intermedio e uno di output, con ognuno di essi che può utilizzare classificatori di varia natura (lineari e non) otteniamo una rete neurale, con molteplici livelli.
Normalmente i livelli intermedi tra quello di input e quello di output sono per semplicità indicati come livelli nascosti (hidden levels).
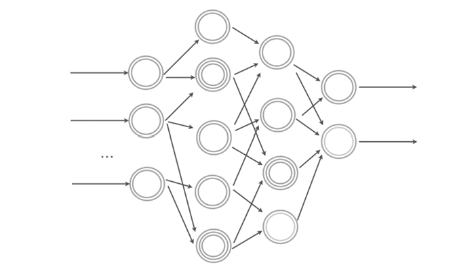
Una rete neurale multilivello DNN (Deep Neural Network) è in grado di predire problemi complessi e gestire molteplici parametri: ovviamente la necessità computazionale aumenta, oltre al fatto che il debug e l’interpretazione dei risultati è inevitabilmente molto più complessa.
Scikit-learn mette a disposizione alcune librerie per modelli basati su reti neurali; esistono poi framework specializzati in deep learning e modelli neurali sviluppati da organizzazioni differenti, quali Tensorflow, MXNet, PyTorch e Keras.
Perché negli ultimi anni il deep learning è diventato importante?
In questi ultimi anni, un nuovo e decisivo impulso all’utilizzo delle reti neurali è derivato da alcune importanti innovazioni tecnologiche introdotte nella “catena del valore del dato” e che hanno avviato una nuova era nel trattamento delle informazioni. In particolare:
- I Big Data: la disponibilità di dataset etichettati di grandi dimensioni (es. ImageNet: milioni di immagini, decine di migliaia di classi).
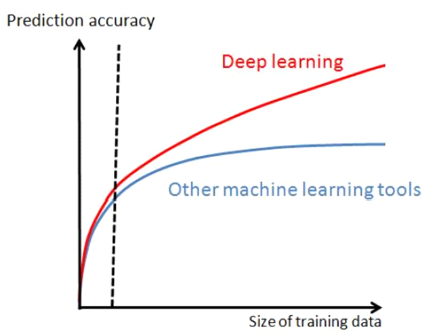
La superiorità delle tecniche di deep learning rispetto ad altri approcci si manifesta quando sono disponibili grandi quantità di dati di training.
 GPU computing: il training di modelli complessi (profondi e con molti pesi e connessioni) richiede elevate potenze computazionali. La disponibilità di GPU con migliaia di core e GB di memoria interna ha consentito di ridurre drasticamente i tempi di training: da mesi a giorni.
GPU computing: il training di modelli complessi (profondi e con molti pesi e connessioni) richiede elevate potenze computazionali. La disponibilità di GPU con migliaia di core e GB di memoria interna ha consentito di ridurre drasticamente i tempi di training: da mesi a giorni.
- Vanishing (or exploding) gradient: la retro-propagazione del gradiente (fondamentale per back propagation) è problematica su reti profonde se si utilizza la sigmoide come funzione di attivazione. Il problema può essere gestito con attivazione Relu (descritta in seguito) e migliore inizializzazione dei pesi (esempio: Xavier inizialization).
Principali tipologie di DNN:
Ci sono varie tipologie di DNN – Deep Neural Network – che possono essere classificate nel seguente modo:
- Modelli feedforward «discriminativi» per la classificazione (o regressione) con training prevalentemente supervisionato:
- CNN – Convolutional Neural Network (o ConvNet)
- FC DNN – Fully Connected DNN (MLP con almeno due livelli hidden)
- HTM – Hierarchical Temporal Memory
- Modelli feedforward con training non supervisionato (modelli «generativi» addestrati a ricostruire l’input, utili per pre-training di altri modelli e per produrre feature salienti):
- Stacked (de-noising) Auto-Encoders
- RBM – Restricted Boltzmann Machine
- DBN – Deep Belief Networks
- Modelli ricorrenti (RNN) (utilizzati per sequenze, speech recognition, sentiment analysis, natural language processing, …):
- RNN – Recurrent Neural Network
- LSTM – Long Short-Term Memory
- Reinforcement learning (per apprendere comportamenti):
- Deep Q-Learning
- Reti neurali Generative (GAN)
Negli articoli che verranno pubblicati nelle prossime settimane, tratteremo ciascuna tipologia di DNN – Deep Neural Network esaminando, di volta in volta, l’impegno di Humanativa sia in termini di progetti realizzati e/o in corso, sia in termini di attività di ricerca e sviluppo della nostra conoscenza.
Articolo scritto da Piero Geraci