BIG DATA SERVELESS
Talend permette di creare processi integrando l’utilizzo di servizi serverless come AWS e AZURE.
La maggiore velocità di esecuzione riduce i costi di elaborazione, mentre l’elaborazione di più dati in parallelo incrementa le prestazioni.
Consente una notevole riduzione di tempo nel processamento e analisi dei Big Data attraverso l’utilizzo di Spark Job e di strumenti come Databricks o Quble.
Tali piattaforme consentono di unificare e integrare le attività dei data scientist e degli ingegneri in tutto il ciclo di vita del Machine Learning, dalla preparazione dei dati alla sperimentazione e all’implementazione di applicazioni ML.
Ciò attraverso:
– L’ integrazione in Talend Studio (rende il processamento dei dati semplice ed efficace)
– Un veloce sviluppo di modelli di machine learning e loro deploy
– Il supporto nativo e una completa portabilità
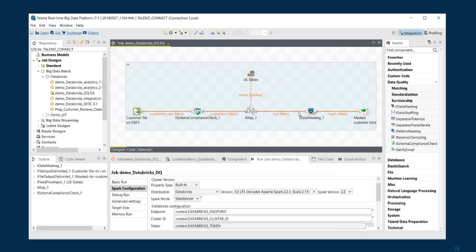
Questo è un esempio di come si può deployare uno Spark Job con distribuzione Databricks.
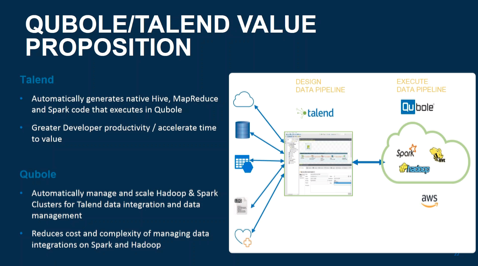
Talend genera automaticamente codice nativo Hive, MapReduce e Spark che verrà esegunto in Qubole o Databricks
Questa integrazione consente di ottenere un elevata produttività di sviluppo accelerando il time to value.
Tale servizi gestiscono in automatico i cluster Hadoop & Spark per Talend Data Integration e Data management. Questo consente di ridurre la complessità e i costi connaturati all’integrazione dei dati su Spark e Hadoop.