

Italian Open data e Reti Neurali per Analisi Predittiva del Prezzo della Benzina
Come è ormai noto, il prezzo della benzina in Italia è tra i più alti nell’Eurozona. Una comparazione con i prezzi europei è visibile nella seguente tabella.
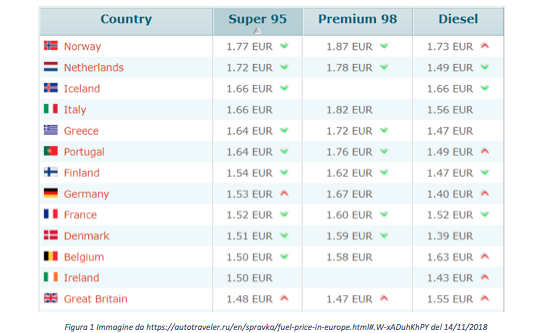
Al fine di poter permettere a tutti gli automobilisti di poter gestire in modo intelligente le loro spese per il carburate, in questo articolo mostreremo come una particolare famiglia di reti neurali, nota come Seq2Seq può essere utilizzata per poter effettuare analisi predittive sul prezzo della benzina in diverse aree di servizio.
Questo articolo è diviso in due sezioni principali. Nella prima, mostreremo una semplice analisi descrittiva dei prezzi della benzina nelle stazioni di servizio del Lazio. Nella seconda invece, mostreremo come le reti neurali possono essere usati per poter predire l’evoluzione del prezzo del carburante.
Italian Open Data
Prima di iniziare con l’analisi è utile spendere del tempo per descrivere il dataset di riferimento.
Negli ultimi anni, lo stato italiano ha investito nell’iniziativa Open Data. Scopo di tale progetto è quello di rilasciare in modo pubblico e gratuito dei set di dati relativi a diversi ambiti. Una descrizione dell’iniziativa open data è disponibile nel sito ufficiale (https://www.dati.gov.it/) mentre una selezione di dataset interessanti è disponibile al seguente link (https://github.com/italia/awesome-italian-public-datasets).
I dati utilizzati all’interno di questo articolo sono relativi al prezzo del carburante che le singolo stazioni di servizio espongono. Tale prezzo infatti è comunicato giornalmente al ministero dello sviluppo economico. Il dataset è disponibile al seguente link (https://www.sviluppoeconomico.gov.it/index.php/it/open-data/elenco-dataset/2032336-carburanti-prezzi-praticati-e-anagrafica-degli-impianti).
I dati forniti dal ministero dello sviluppo economico sono disponibili per ogni trimestre nell’intervallo temporale 2015-2018. Per ciascun è possibile ottenere un file compresso. All’interno di ciascun file compresso sono disponibili dei file .csv, uno per ogni giorno del trimestre. Ciascun file csv contiene il prezzo del carburante di ciascuna stazione di servizio operativa in tale giorno.
Sul sito sono inoltre presenti daty aggiuntive utili ad arricchire il contenuto informativo. Infatti, per ciascuna stazione di servizio informazioni geografiche (coordinate GPS, comune, via, provincia, etc..) sono disponibili. Inoltre, è anche noto il marchio associato a ciascun distributore.
Data Visualization tramite Qlik Sense Desktop
Prima di utilizzare i nostri dati per analisi predittive, dei plot utili ad avere una overview generale dai dati sono presentati. Per effettuare tale task Qlik Sense Desktop (https://www.qlik.com/us/) è stato utilizzato.
Poiché in questo dataset sono presenti informazioni geografiche sui singolo distributore, abbiamo scelto di rappresentare le informazioni tramite l’ausilio di mappe geografiche. Al fine di semplificare la fruizione dell’analisi, ci siamo concentrati sui distributori presenti nei comuni della regione Lazio utilizzando i prezzi ottenuti dall’ultima data disponibile del dataset: 2018–06–30.
Poichè, Qlik Sense, standard, non gestisce informazioni geografiche a livello dei singoli comuni Italiani. A tal proposito è stato necessario importare i confini di ciascun comune grazie all’ausilio di file KML.
Nel seguente blog (https://localmapping.wordpress.com/) sono disponibili un insieme di file KLM contenente, per ogni regione, i confini dei suoi comuni (https://localmapping.wordpress.com/2008/11/20/i-confini-amministrativi-degli-8101-comuni-ditalia-al-2001/).
Il file KML relativo ai comuni della regione Lazio è stato importato in Qlik Sense insieme alle informazioni relative ai prezzi e all’anagrafica dei singoli distributori. I seguenti campi sono stati usati per effettuare i join tra tutte le informazioni:
KML File (Lazio.Name) — Anagrafica Impianti (Comune)
Anagrafica Impianti (idImpianto) — Prezzo Alle (idImpiato)

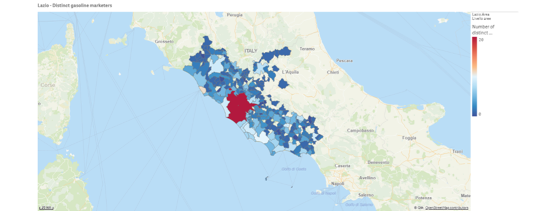
Di seguito mostriamo un esempio di plot nel quale mostriamo, per ogni comune, il prezzo medio della benzina al self service.

Possiamo inoltre verificare la varietà di brand diversi disponibili per ciascun comune.
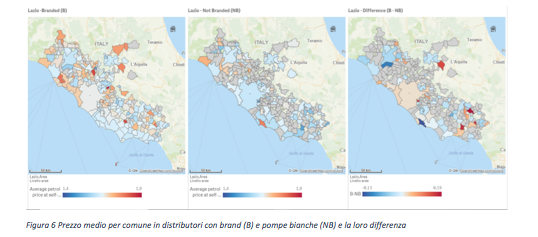
Un’analisi interessante è verificare se sono presenti differenze di prezzo tra distributori appartenenti a brand noti (B) e pompe bianche (NB).
In questa sezione abbiamo mostrato un sotto insieme di analisi grafiche che possono essere effettuate su tale dataset. In altri articoli effettueremo analisi più dettagliate e ricche
Reti Neurali Seq2Seq in Keras per Analisi Predittive
In questa sezione, mostreremo come è possibile utilizzare una particolare famiglia di reti neurali, nota come Seq2Seq per effettuare un’analisi predittiva del prezzo della benzina, al self-service, nelle singolo stazioni di servizio.
Una delle prime domande da porsi è: Perché delle reti neurali e non dei modelli ARIMA per analizzare il comportamento di serie storiche?
La risposta a tale quesito è relativa alla natura del dataset. Infatti, nel sottoinsieme usato per la nostra analisi sono presenti 27042 differenti aree di servizio, ciascuna delle quali ha la sua “serie storica” di prezzi di benzina. Utilizzando dei modelli ARIMA è necessario creare un modello per ogni serie storica, e dunque 27042 modelli. Questo approccio è difficile da adoperare. Per poter dunque risolvere tale limite, è possibile utilizzare le reti neurali Seq2Seq che hanno la peculiarità di “capire” l’andamento di diverse serie storiche. Tramite una sola rete neurale è dunque possibile capire l’andamento ed il comportamento di 27042 serie storiche diverse.
In questo articolo non offriremo una descrizione dettagliata delle reti Seq2Seq. La rete adoperata per effettuare la nostra analisi è brillantemente descritta in questo articolo (https://github.com/JEddy92/TimeSeries_Seq2Seq/blob/master/notebooks/TS_Seq2Seq_Conv_Intro.ipynb). Giusto per dare una intuizione, tale rete è capace di apprendere il comportamento “futuro” della serie leggendo cosa è accaduto prima tramite l’utilizzo di operatori di convoluzione 1 dimensionali.
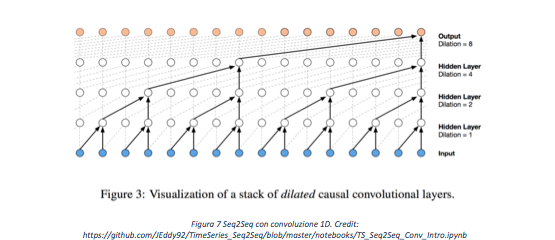
Gli step precedenti possono dunque essere utilizzati per poter effettuare la predizione dello step successivo.
All’interno di questo articolo abbiamo scelto di predire un periodo di 2 settimane (14 giorni) utilizzando informazioni dei 1024 giorni precedenti. Al fine di poter aiutare la rete neurale ad apprendere i dati sui quali imparare e quelli sui quali predire hanno un overlap di un giorno. Tale sovrapposizione è usato come conoscenza di partenza per il processo predittivo.
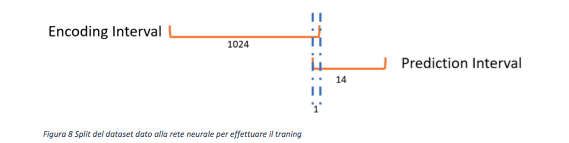
Dopo il processo di training la rete neurale è stata eseguita per poter effettuare la predizione del prezzo su alcune stazioni di rifornimento.
Il risultato predetto con la rete neurale, per 4 diverse stazioni di rifornimento è visibile nella seguente figura.
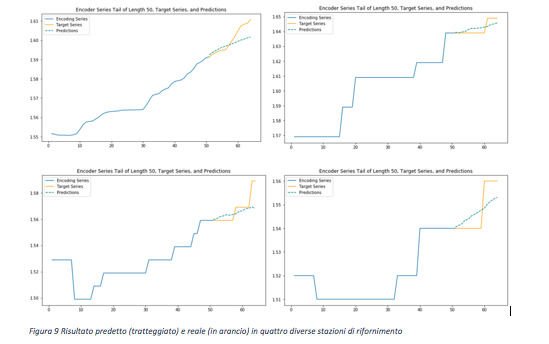
Dai plot mostrati si vede come la rete neurale è capace, con una buona approssimazione, di poter predire il prezzo della benzina in ogni singola stazione di servizio con due settimane di anticipo.
Conclusioni
In questo articolo abbiamo mostrato le potenzialità della data visualization, tramite Qlik Sense, in combinazione con le reti neurali. Abbiamo inoltre mostrato come il progetto Open Data del governo italiano è una risorsa preziosa di dati.
Questo è ovviamente un primo passo per altre potenziali e più interessanti analisi. In altri articoli daremo una descrizione più dettagliata delle possibili tecniche di data visualization e machine learning che possono essere applicate su tali dataset.